'리스트보다 NumPy의 배열이 훨씬 빠르다'
먼저 파이썬의 리스트는 여러 개의 값들을 저장할 수 있는 자료구조로서 강력하고 활용도가 높다. 리스트는 다양한 자료형의 데이터를 여러 개 저장할 수 있으며, 데이터를 변경하거나 추가, 제거할 수 있다.
하지만 데이터 과학에서는 파이썬의 기본 리스트로 충분하지 않다. 데이터를 처리할 때는 리스트와 리스트 간의 다양한 연산이 필요한데, 파이썬 기본 리스트는 이러한 기능이 부족하여 리스트를 다루는 일은 연산 속도도 빠르지 않다. 따라서 데이터 과학자들은 기본 리스트 대신에 Numpy를 선호한다.
NumPy는 대용량의 배열과 행렬 연산을 빠르게 수행하며, 고차원적인 수학 연산자와 함수를 포함하고 있는 파이썬 라이브러리다.
표에서 알 수 있듯이 NumPy의 배열은 주황색으로 표시된 파이썬의 리스트에 비하여 처리속도가 매우 빠름을 알 수 있다.
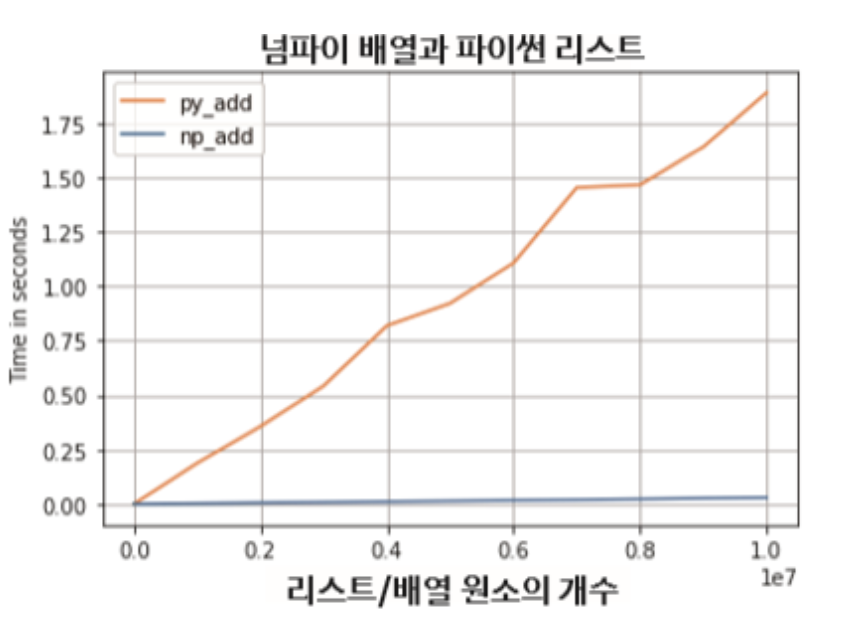
그렇다면 왜 NumPy의 배열이 리스트보다 빠를까?
넘파이가 계산을 쉽고 빠르게 할 수 있는 데에는 이유가 있다. 넘파이는 각 배열마다 타입이 하나만 있다고 생각한다. 다시 말하면, 넘파이의 배열 안에는 동일한 타입의 데이터만 저장할 수 있다. 즉 정수면 정수, 실수면 실수만을 저장할 수 있는 것이다. 파이썬의 리스트처럼 여러 가지 타입을 섞어서 저장할 수는 없다. 만약 여러 가지 타입을 섞어서 넘파이의 배열에 전달하면 넘파이는 이것을 전부 문자열로 변경한다. 예를 들어서 다음 배열은 문자열 배열이 된다.
tangled = np.array([100, 'test', 3.0, False])
print(tangled)
['100' 'test' '3.0' 'False']이렇게 동일한 자료형으로만 데이터를 저장하면 각각의 데이터 항목에 필요한 저장공간이 일정하다. 따라서 몇 번째 위치에 있는 항목이든 그 순서만 안다면 바로 접근할 수 있기 때문에 빠르게 데이터를 다룰 수 있는 것이다.
덧붙여서 이렇게 원하는 위치에 바로 접근하여 데이터를 읽고 쓰는 일을 임의 접근(random access)라고 한다. 우리가 주기억 장치로 많이 쓰는 기억장치가 임의 접근 기억장치(random access memory)이고 줄여서 RAM이라 한다. 임의 접근이 가능하기 때문에 RAM은 기억장치가 회전하면서 원하는 위치의 데이터를 읽는 하드디스크보다 빠른 것 이다.
'ETC' 카테고리의 다른 글
| [python] 클래스 변수와 __dict__ (0) | 2021.12.14 |
|---|---|
| [python] Broadcasting(브로드캐스팅) (0) | 2021.12.14 |
| [python] 클래스의 특별한 메서드 (0) | 2021.12.12 |
| 모의 객체(Mock Object) 란? (0) | 2021.11.19 |
| [python] 가변 매개변수(Arrbitary Argument) 란? (0) | 2021.11.09 |
| mac M1에서 안드로이드 애뮬레이터 사용하기 (0) | 2021.11.06 |

댓글